Overview of the Neon object hierarchy
Managing your Neon project requires an understanding of the Neon object hierarchy. The following diagram shows how objects in Neon are related. See below for a description of each object.
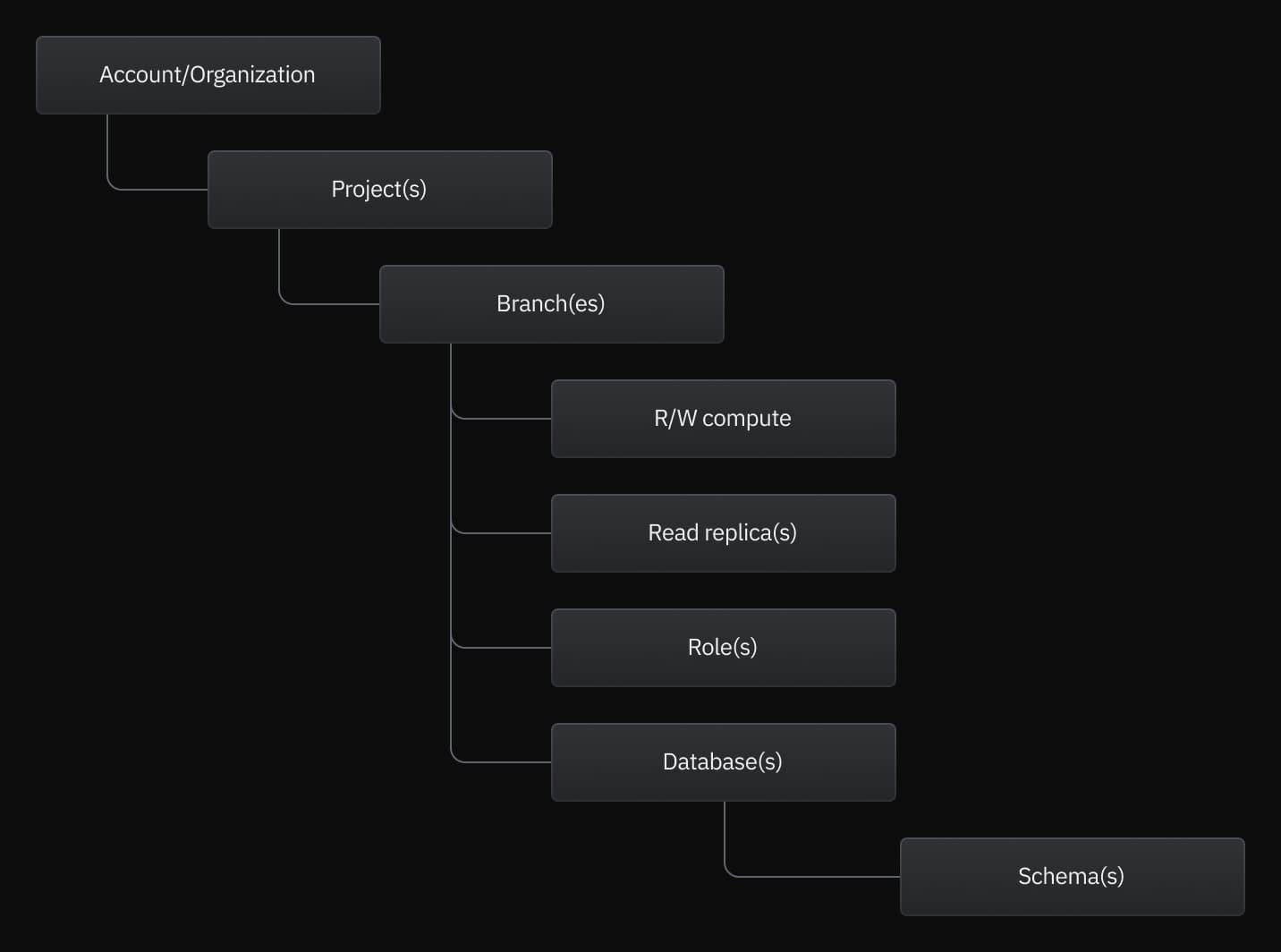
Neon account
This is the Neon account you signed up with. Neon supports signing up with an email, GitHub, Google, or partner account.
API keys are global and belong to the Neon account. API keys are used with the Neon API to create and manage Neon projects or objects within a Neon project. While there is no strict limit on the number of API keys you can create, we recommend keeping it under 10,000 per Neon account. For more about API keys, see Manage API keys.
Organizations
Neon's Organizations feature allows you organize and manage a team's projects under a single Neon account — with billing, role management, and project transfer capabilities all in one accessible location in the Neon Console.
Projects
A project is a container for all objects except for API keys, which are global and work with any project owned by your Neon account. Branches, computes, roles, and databases belong to a project. A Neon project also defines the region where project resources reside. A Neon account can have multiple projects, but plan limits define the number of projects per Neon account. For more information, see Manage projects.
Default branch
Data resides in a branch. Each Neon project is created with a default branch called main. This initial branch is also your project's root branch, which cannot be deleted. After creating more branches, you can designate a different branch as your default branch, but your root branch cannot be deleted. You can create child branches from any branch in your project. Each branch can contain multiple databases and roles. Plan limits define the number of branches you can create in a project and the amount of data per branch. To learn more, see Manage branches.
R/W computes and Read Replicas
A compute is a virtualized computing resource that includes vCPU and memory for running applications. In the context of Neon, a compute runs Postgres. When you create a project in Neon, a primary R/W (read/write) compute is created for a project's default branch. Neon supports both R/W and Read Replica computes. A branch can have a single primary R/W compute but supports multiple Read Replica computes. To connect to a database that resides on a branch, you must connect via a R/W or Read Replica compute associated with the branch. Your Neon plan defines the resources (vCPU and RAM) available to your R/W and Read Replica computes. For more information, see Manage computes. Compute size, autoscaling, and scale to zero are all settings that are configured for R/W and Read Replica computes.
Roles
In Neon, roles are Postgres roles. A role is required to create and access a database. A role belongs to a branch. There is a limit of 500 roles per branch. The default branch of a Neon project is created with a role named for your database. For example, if your database is named neondb, the project is created with a role named neondb_owner. This role is the owner of the database. Any role created via the Neon Console, CLI, or API is created with neon_superuser privileges. For more information, see Manage roles.
Databases
As with any standalone instance of Postgres, a database is a container for SQL objects such as schemas, tables, views, functions, and indexes. In Neon, a database belongs to a branch. If you do not specify your own database name when creating a project, the default branch of your project is created with a ready-to-use database named neondb. There is a limit of 500 databases per branch. For more information, see Manage databases.
Schemas
All databases in Neon are created with a public schema, which is the default behavior for any standard PostgreSQL instance. SQL objects are created in the public schema, by default. For more information about the public schema, refer to The Public schema, in the PostgreSQL documentation.