Neon introduced autoscaling for serverless Postgres to the world over a year ago, enabling your applications to handle peak demand without incurring peak infrastructure costs 24/7. Our autoscaling feature performs zero-downtime vertical scaling of your Postgres instance, provisioning extra CPU and memory when your workload needs it and scaling down to reduce costs when possible.
Almost a third of our customers use autoscaling today. Recrowd, a Neon customer, recently shared how Neon’s autoscaling provides them with the peace of mind that they’re ready to handle fluctuating demand.
Implementing autoscaling for Postgres is no easy feat though, and we’ve learned many lessons by bringing over 700,000 databases under management this past year and a half. We’d like to take this opportunity to thank everyone building on Neon — your valuable feedback has helped grow and shape our platform.
As part of our thanks, we’d like to share some of the challenges we’ve overcome and give you a sneak peek into what’s next for Neon’s autoscaling.
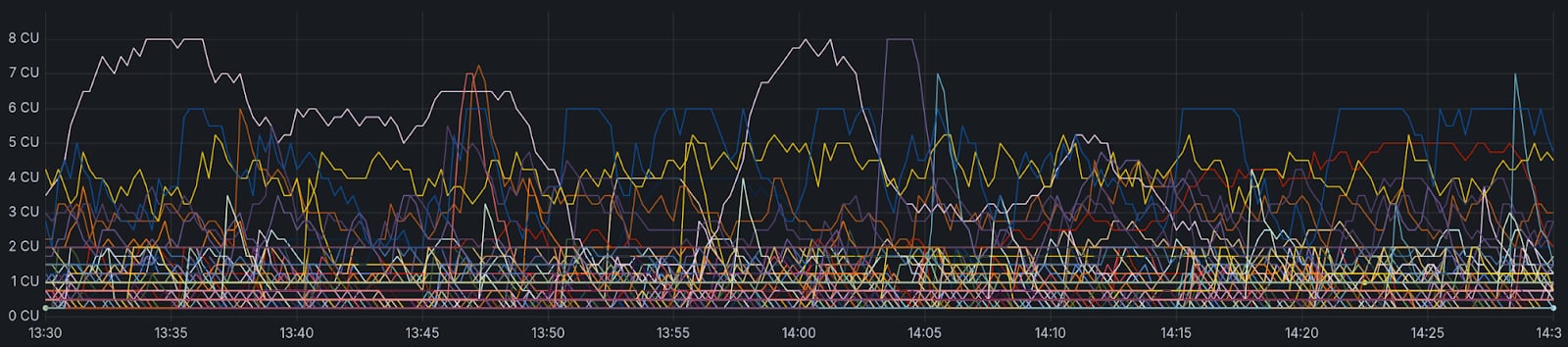
An hour of autoscaling by a selection of your databases, captured from real production data while writing this post. Each line is a single endpoint, with a height equal to provisioned compute units.
Architecture of Autoscaling: A refresher
Neon deploys each Postgres instance as a virtual machine (VM) in one of our Kubernetes clusters. If you’re familiar with Kubernetes, you might wonder why we use virtual machines instead of containers — after all, containers are the standard way to run workloads in Kubernetes, and VMs aren’t natively supported.
In short, we chose VMs because they:
- Provide strong isolation boundaries
- Support dynamic adjustment of assigned resources, which is necessary for autoscaling without restarting Postgres
- Can support seamless live migration, allowing us to rebalance across nodes
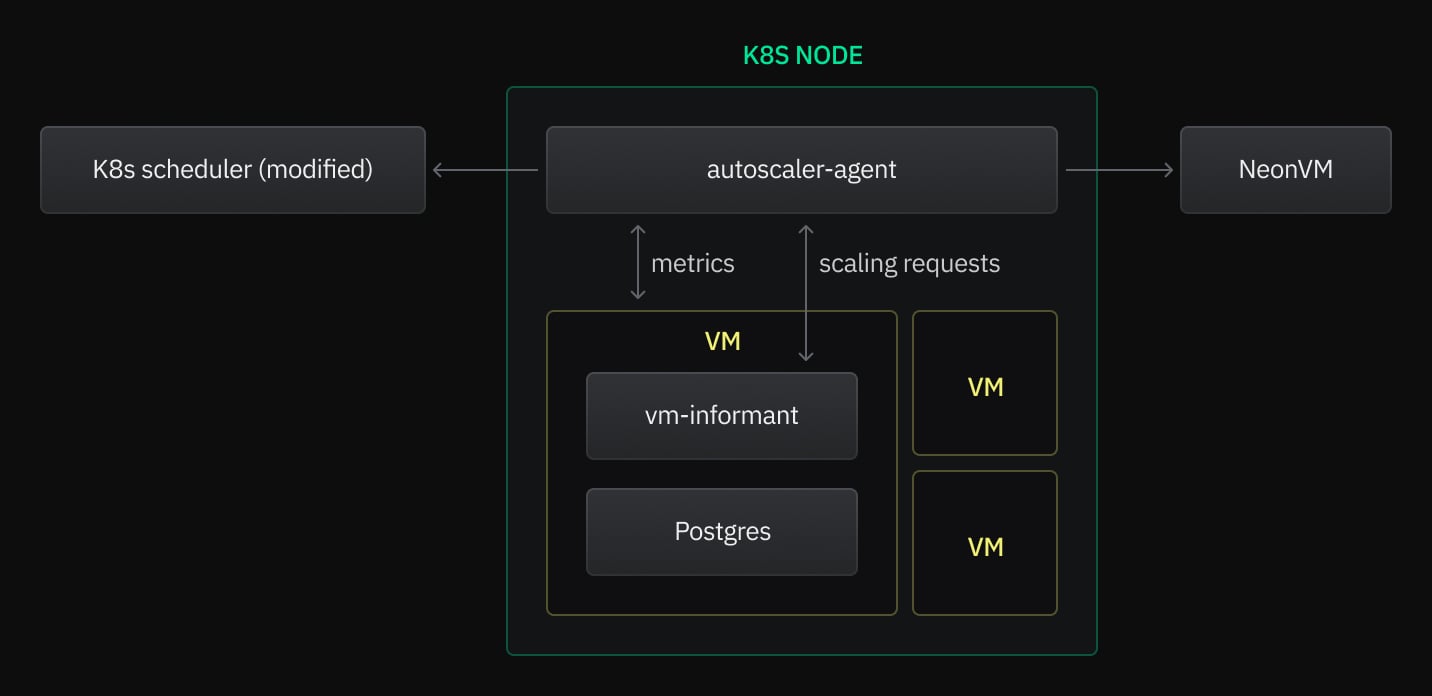
Since Kubernetes doesn’t natively support VMs, and preexisting VMs-in-Kubernetes tools didn’t meet our requirements, we created NeonVM. This provides a custom resource definition (CRD) and controller for deploying and managing virtual machines in our Kubernetes clusters, including the ability to dynamically scale the CPU and memory available to them in-place.
To implement the scaling logic of autoscaling, we use our autoscaler-agent — a daemon we deploy on each Kubernetes node to monitor metrics for each Postgres VM and make scaling decisions based on those metrics. The autoscaler-agent also works in conjunction with our modified Kubernetes scheduler to prevent unintentionally overcommitting resources, making sure we don’t run out of resources on the host node.
The autoscaler-agent also communicates with the vm-monitor, a small program inside the VM. The vm-monitor continuously monitors Postgres’ resource usage and will request upscaling on its behalf when there’s an imminent need, e.g., if a query is about to exhaust all available memory. vm-monitor is also responsible for adjusting the size of our Local File Cache in Postgres when scaling occurs, to take advantage of added resources.
For more background information, read our original Scaling Serverless Postgres article.
Autoscaling at Scale
Here’s a quick recap of some challenges we ran into. Many of these engineering challenges warrant an article of their own — and this doesn’t even include the kernel panics or I/O throttling we worked to resolve in our quest for stability!
Let us know through Discord or X if you’d like to hear more about these.
Cgroup Signals and Memory Scaling
Our initial memory scaling implementation ran Postgres in a control group (cgroup) inside the VM, and listened to memory.high events to trigger upscaling. In theory, this makes sense — we can get notified almost instantly when Postgres’ memory usage exceeds a defined threshold, scale up before memory runs out, and then increase the threshold. In practice, we had issues with this approach because memory.high isn’t really meant to be used that way — it’s best interpreted as a soft upper-bound on memory usage, above which the kernel will start forcing the processes in the cgroup into memory reclamation and aggressively throttling them.
To fix these, we simplified — just polling the Postgres cgroup’s memory usage 100ms and requesting more if it looks like it’ll run out soon. We found this was more predictable – and critically, more stable – than trying to use memory.high. And while it can’t always react fast enough, there’s limits elsewhere in the system, too — ACPI memory hotplug isn’t always instant, either. More on that later.
Scaling Down to Zero TPS
Just before Neon’s last offsite in November, we discovered a strange issue during internal pre-release benchmarking: Under certain circumstances, communication appeared to stall between the Postgres instance and its safekeepers, for up to a minute. At the same time, the ongoing pgbench run would start reporting that it was making no progress, i.e., 0 TPS (transactions per second).
We quickly identified that the issue only affected autoscaling-enabled endpoints. The issue wasn’t consistently reproducible, and when we did see it, we had a limited window during which we could interrogate the state of the VM. To make matters worse, it sometimes seemed as if looking at the problem caused it to resolve! Occasionally, when we’d run ps to see the state of all processes inside the VM, pgbench would immediately resume as if nothing had happened.
We build a custom Linux kernel, so after some debugging with kallsyms during the offsite, we found that both Postgres and the kernel’s acpi_hotplug worker were stuck in a suspicious 100-millisecond sleep, deep in the same memory allocation code path. Suspecting this could be a kernel bug, we tried testing with a newer kernel version — and after running a comprehensive suite of tests on both versions, we found that the issue was fully resolved by updating the kernel.
What’s Next for Autoscaling Postgres at Neon
We’ve been busy throughout this first year of autoscaling prioritizing its stability, but as we look towards further improvement, we’ve turned our focus on expanding the set of workloads that autoscaling is a great fit for.
And while in the medium-term, we have some deeper technical changes coming (virtio-mem, free page reporting, and DAMON, oh my!) — we wanted to give you a sneak peek of some improvements coming soon.
Smarter Autoscaling using Local File Cache Metrics
Neon’s architecture separates storage and compute. It’s an integral part of what enables us to autoscale and dramatically reduce cold start times for serverless Postgres. Of course, accessing pages across the network can result in increased query latency, so Neon’s Postgres has a Local File Cache (LFC) that acts as a resizable extension of Postgres’ shared buffers.
Picking the right size for the cache is crucial — with certain OLTP workloads, we see a stepwise effect based on whether the working set fits into cache, sometimes with a 10x increase in performance from just a marginal increase in LFC size. A corollary to this is that the ideal endpoint size is often just big enough to fit the working set size, but no larger.
However, determining the right LFC size on the fly is challenging. Cache hit ratio isn’t a reliable indicator of what the size should be, and there’s little benefit to scaling up if the working set wouldn’t fit into cache either way.
To help larger workloads stay performant, we’re currently working on augmenting our scaling algorithm with metrics from the LFC — specifically, using a HyperLogLog estimator for working set size based on the number of unique pages accessed.
In the meantime, you can read more about sizing your Postgres database on Neon for optimal LFC usage in our documentation.
Accommodating Rapid Memory Allocation with Swap
With the way autoscaling works today, there’s fundamental limits to how fast we can react to increased memory usage — and as a result, we’ve seen that workloads allocating large blocks of shared memory can sometimes fail, or even get hit by OOMs.
We’ve considered a couple of strategies, and in the end landed on the combination of adding swap1 and disabling memory overcommitting2.
What practical applications does this have? Well, pgvector 0.6 implemented a parallel Hierarchical Navigable Small World (HNSW) index build feature. We wrote about how using this feature can result in 30x faster index builds. As a consequence of supporting parallel index building, pgvector 0.6 switched to allocating all its memory up-front — without these changes, we found it’d fail with inscrutable errors if the dataset was too large.
From an implementation perspective though, it’s not trivial. To support blazingly fast cold starts, we keep a pool of pre-created VMs, waiting to be assigned an endpoint to run — unfortunately this means that we don’t know how much swap the VM will need until after it’s created.
Thankfully, the solution’s not so bad — we can mount an empty disk for swap, and when the VM is assigned an endpoint, mkswap with the desired size and swapon. All mkswap does is write the header page (which itself is only 4KiB on most systems), and swapon is only expensive for non-contiguous disk space (like swapfiles), so this ends up quick enough to be included in the hot path.
We’re in the process of rolling this out over the next couple of weeks — including new observability into swap usage, to help you assess if your endpoint’s scaling limits should be increased.
Conclusion
Building a truly cloud-native serverless Postgres platform is challenging, but we’ve risen to the challenge at Neon. Our engineering team has been hard at work running Postgres at scale and enhancing it with cutting-edge features. Autoscaling – alongside branching, point-in-time restore, and time travel queries – are just the start of the unique features made possible by Neon’s separation of storage and compute.
Are you using Neon’s autoscaling? We’d love your feedback and to hear about what you’re building with Neon. Follow us on X, join us on Discord, and let us know how we can help you build the next generation of applications.
- Historically, the reason we didn’t have swap is because we were concerned about performance – for a long time we used EBS-backed nodes with relatively little IOPS capacity (because storage is separate from compute), so we were concerned that swap may do more harm than good. But we eventually switched away from EBS to local SSDs, which are tons faster, so this is no longer a concern.
- This is quite common for database software, and indeed is what’s typically recommended for Postgres. We initially were concerned about potential interactions with memory hotplug, but through testing found it to be more stable than the alternative.